Method
Method overview.
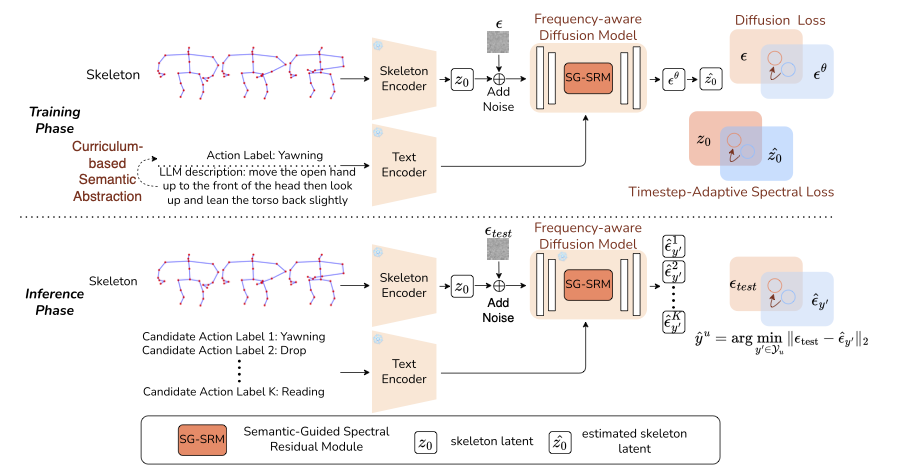
Zero-Shot Skeleton Action Recognition relies on semantic guidance to recognize unseen actions, but diffusion-based approaches still suffer from spectral bias: they preserve coarse pose structure while oversmoothing the high-frequency dynamics that distinguish fine-grained actions. FDSM addresses this issue with three coordinated components. A Semantic-Guided Spectral Residual Module restores discriminative high-frequency content in the latent space. A Timestep-Adaptive Spectral Loss aligns spectral supervision with the coarse-to-fine denoising trajectory. A Curriculum-based Semantic Abstraction strategy transfers rich LLM-generated motion descriptions into sparse-label inference. Across NTU RGB+D, PKU-MMD, and Kinetics-skeleton benchmarks, FDSM consistently improves over prior state of the art and produces more faithful motion representations.
Method
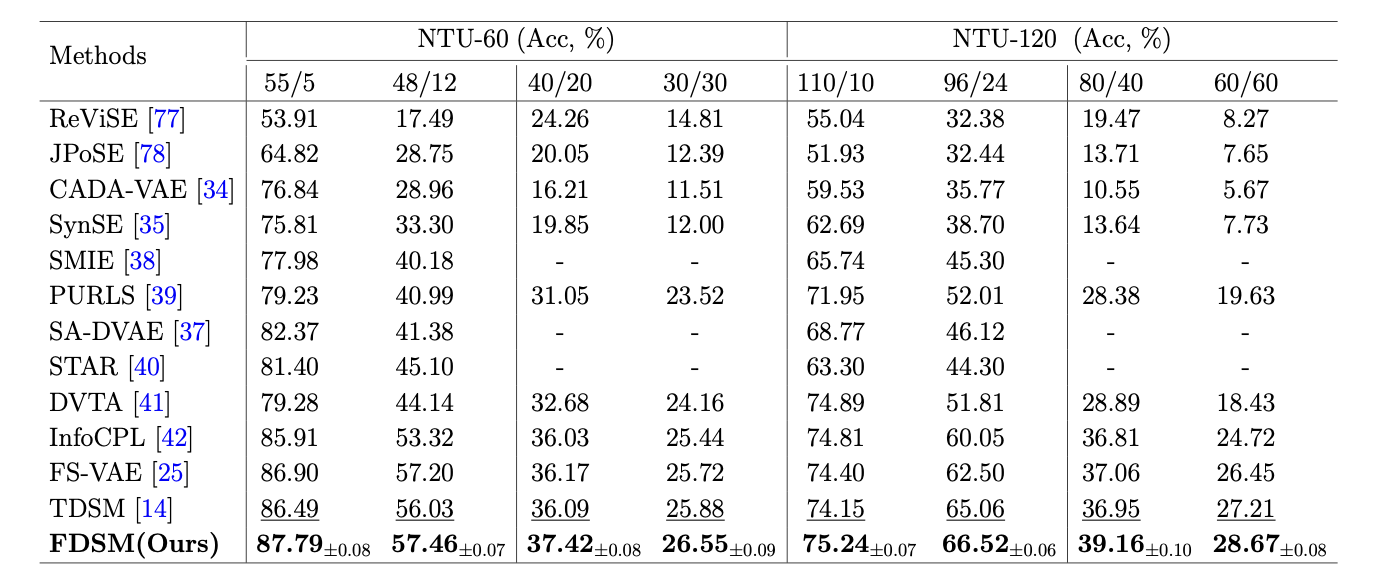
Results
@article{zhou2026fdsm,
title = {Frequency-Enhanced Diffusion Models: Curriculum-Guided Semantic Alignment for Zero-Shot Skeleton Action Recognition},
author = {Yuxi Zhou and Zhengbo Zhang and Jingyu Pan and Zhiyu Lin and Zhigang Tu},
year = {2026},
note = {Project page version. Please update with the final publication metadata.},
url = {https://github.com/yuzhi535/FDSM}
}